One of my daily non-work related tasks is checking the prices of products from Amazon.co.uk that family members of myself are after at a cheap price. This is generally accomplished by either loading up the Amazon.co.uk individual product pages or adding all the items to an Amazon wishlist and loading that up.
So I got to thinking there has got to be a quicker / more efficient way to monitor product pricing on Amazon.co.uk, and that has led me to creating an Amazon.co.uk Price Checker in Python. This is only more first version, I want to expand it in the future to:
– Check multiple ASIN (Amazon IDs) in future by listing the ASINs in a list and then progressing through the list and adding the ASINs to the end of a basic Amazon URL.
– Notify if a price has reached / gone below a certain price (e.g. if the product drops below £20.00)
– Run periodically (e.g. every day at 6pm)
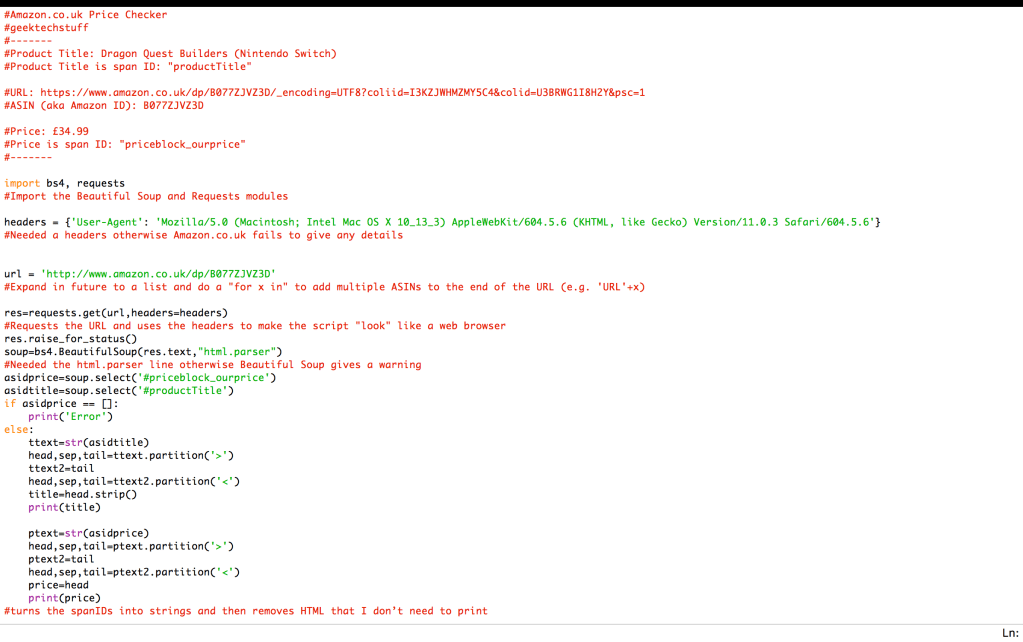
For my test example I am checking the price of “Dragon Quest Builders” on the Nintendo Switch, as of today (21st February 2018) it is £34.99. The title and price spanIDs were needed from the pages HTML so that they could be used in the script. I’ve left the details of the test example in the comments at the top of the script; they are not needed but are just a reference for me.
My script makes use of the Beautiful Soup and Requests modules for Python. I’ve commented (#) were I feel appropriate so that I now why I did something.
#Amazon.co.uk Price Checker
#geektechstuff
#——-
#Product Title: Dragon Quest Builders (Nintendo Switch)
#Product Title is span ID: “productTitle”
#URL: https://www.amazon.co.uk/dp/B077ZJVZ3D/_encoding=UTF8?coliid=I3KZJWHMZMY5C4&colid=U3BRWG1I8H2Y&psc=1
#ASIN (aka Amazon ID): B077ZJVZ3D
#Price: £34.99
#Price is span ID: “priceblock_ourprice”
#——-
import bs4, requests
#Import the Beautiful Soup and Requests modules
headers = {‘User-Agent’: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/604.5.6 (KHTML, like Gecko) Version/11.0.3 Safari/604.5.6’}
#Needed a headers otherwise Amazon.co.uk fails to give any details
url = ‘http://www.amazon.co.uk/dp/B077ZJVZ3D’
#Expand in future to a list and do a “for x in” to add multiple ASINs to the end of the URL (e.g. ‘URL’+x)
res=requests.get(url,headers=headers)
#Requests the URL and uses the headers to make the script “look” like a web browser
res.raise_for_status()
soup=bs4.BeautifulSoup(res.text,”html.parser”)
#Needed the html.parser line otherwise Beautiful Soup gives a warning
asidprice=soup.select(‘#priceblock_ourprice’)
asidtitle=soup.select(‘#productTitle’)
if asidprice == []:
print(‘Error’)
else:
ttext=str(asidtitle)
head,sep,tail=ttext.partition(‘>’)
ttext2=tail
head,sep,tail=ttext2.partition(”)
ptext2=tail
head,sep,tail=ptext2.partition(‘<')
price=head
print(price)
#turns the spanIDs into strings and then removes HTML that I don’t need to print




One response to “Amazon.co.uk Price Checker (Part 1)”
[…] on my price checker (see part 1) I’ve now added in an option asking how much spends (a.k.a pocket money) is available and […]
LikeLike