Continuing on from my post looking at Data Architecture / Data Modelling, I am now going to look at data, data lakes and data warehouses by turning my notes into this blog post.
Data
Data can include emails, phone calls, financial transactions, sensor readings, metrics, logs, pretty much everything. When referring to corporate data, it means all data within the corporation. Data can then be broken into:
Structured
Structured data is well defined and typically repetitive. Examples include names, addresses, geolocations, credit card numbers and telephone numbers. The data fits a defined data model or format.
Unstructured
Unstructured data is not well defined and can be split into repetitive unstructured data and non-repetitive unstructured data. Repetitive unstructured data examples include sensor readings / metrics. Non-repetitive unstructured data examples include emails (as the length and content can change per email).
Discrete Data
Discrete data is data that must take on a value from a specific set of numbers. For example, the number of children in a family is discrete data as it must be a positive integer or zero (0, 1, 2, 3, 4, etc…) and not a decimal of fraction (e.g., families cannot have .2 of a child).
The Great Divide
The Great Divide is the division line, or demarcation, between unstructured repetitive data and structured repetitive data. The Great Divide represents the big difference between the two types, how they can be analysed and how they can be managed.
Where Does A Data Lake Come In?
Everything (e.g., IoT devices, Customer Relationship Management systems, stock systems) creating data sends the data somewhere. Imagine all the data streams flowing into one location and that is a data lake – a very large repository of raw data that is very easy to (figuratively) drown in.
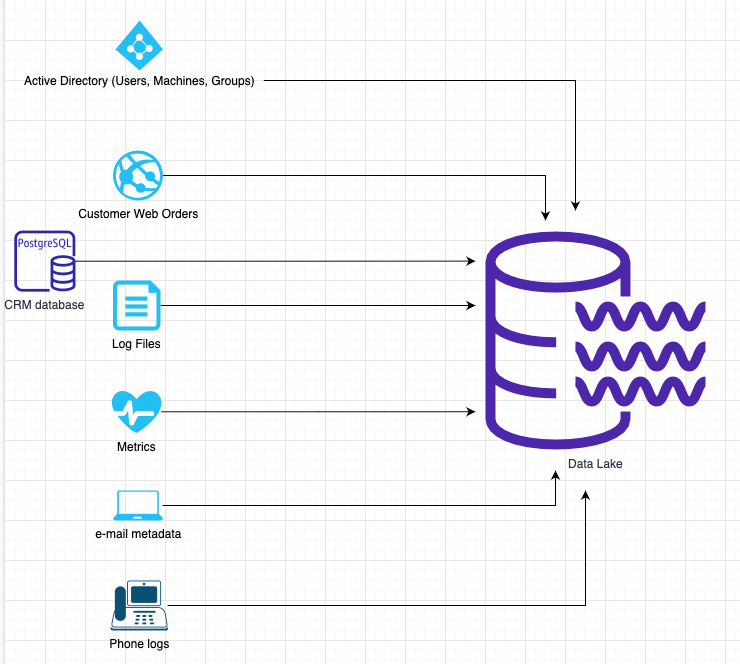
All the raw data in the lake then needs processing via Extraction Transformation Loading (ETL), which transforms (shapes) the data into a useable resource and then loads that resource into an Enterprise Data Warehouse (EDW). An EDW is also known as a Data Warehouse. The DataWarehouse then creates subsets of the resources called Data Marts for users to use (e.g., use for data analysis). A Data Mart is typically oriented to a specific business team or business need.
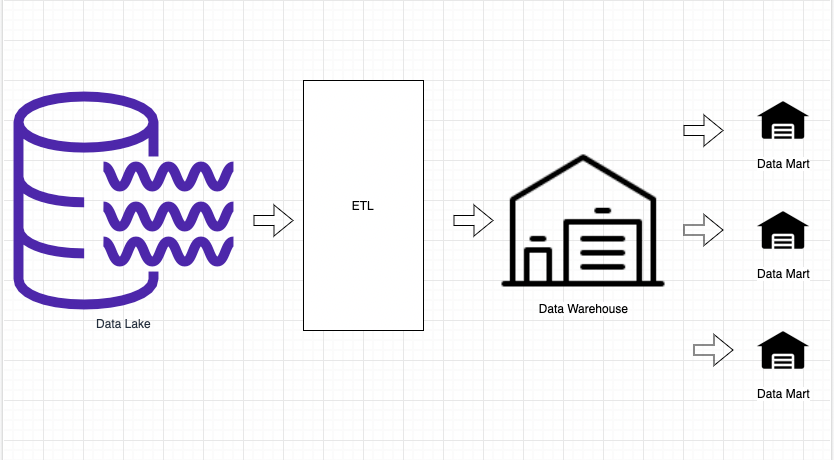
Keeping the lake analogy going – the various streams (data streams) flow into a lake (data lake) creating a massive source of water (data). The water is then filtered (ETL) and turned into products (bottled water, ice cubes) to be stored in the warehouse (Data Warehouse). The products are then sent from the warehouse (Data Warehouse) to local shops/marts (Data Mart). Customers (Users) then interact with the products in the shop/mart (Data Mart).





One response to “Data, Data Lakes and Data Warehouses (Notes)”
[…] NoSQL can mean Not Only SQL, or NOt SQL. NoSQL is used in non-relational or distributed database systems to store structured, semi-structured or unstructured data. […]
LikeLike